RisingWave Open Lake
Managed Iceberg™ Tables,
Built for Everyone
Trusted by 1,000+ Data-Driven Organizations
for Real-time Analytics






in 3 Simple Steps
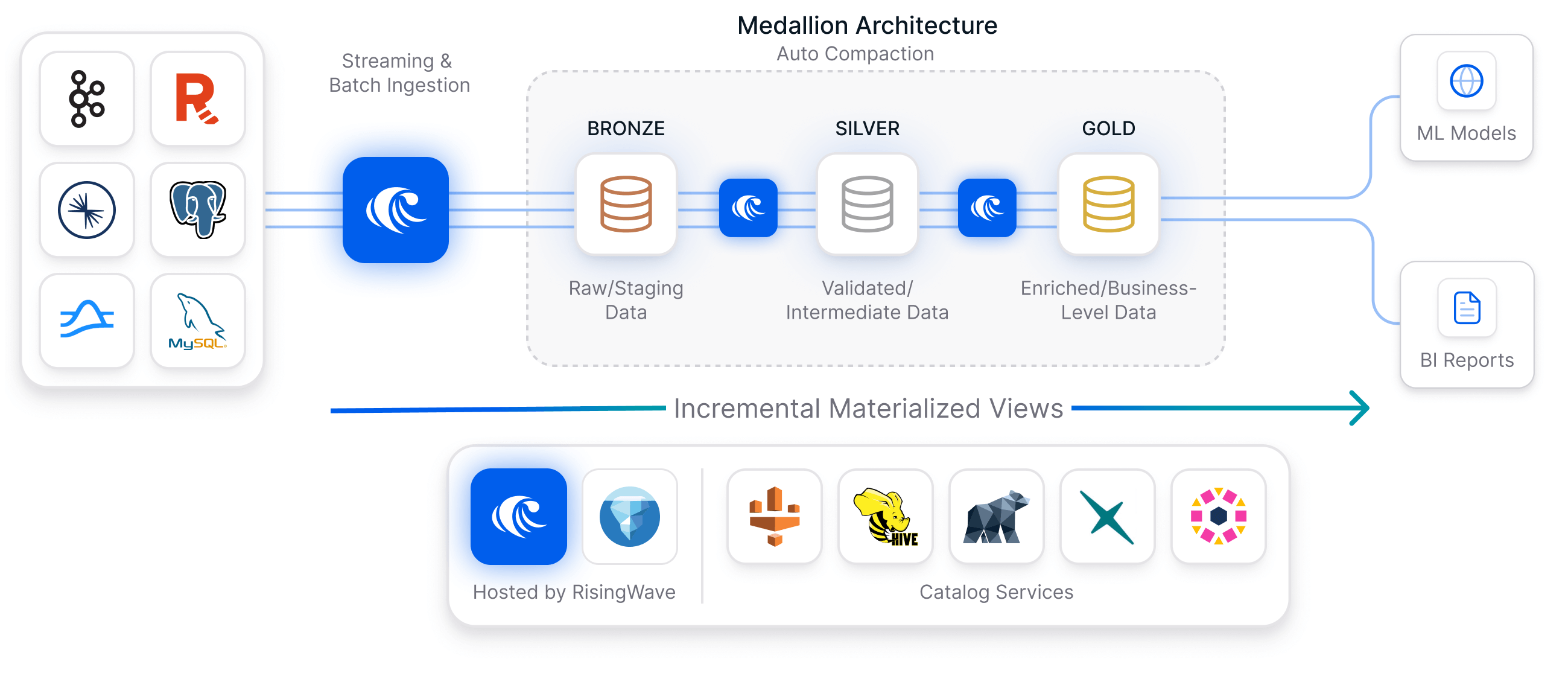
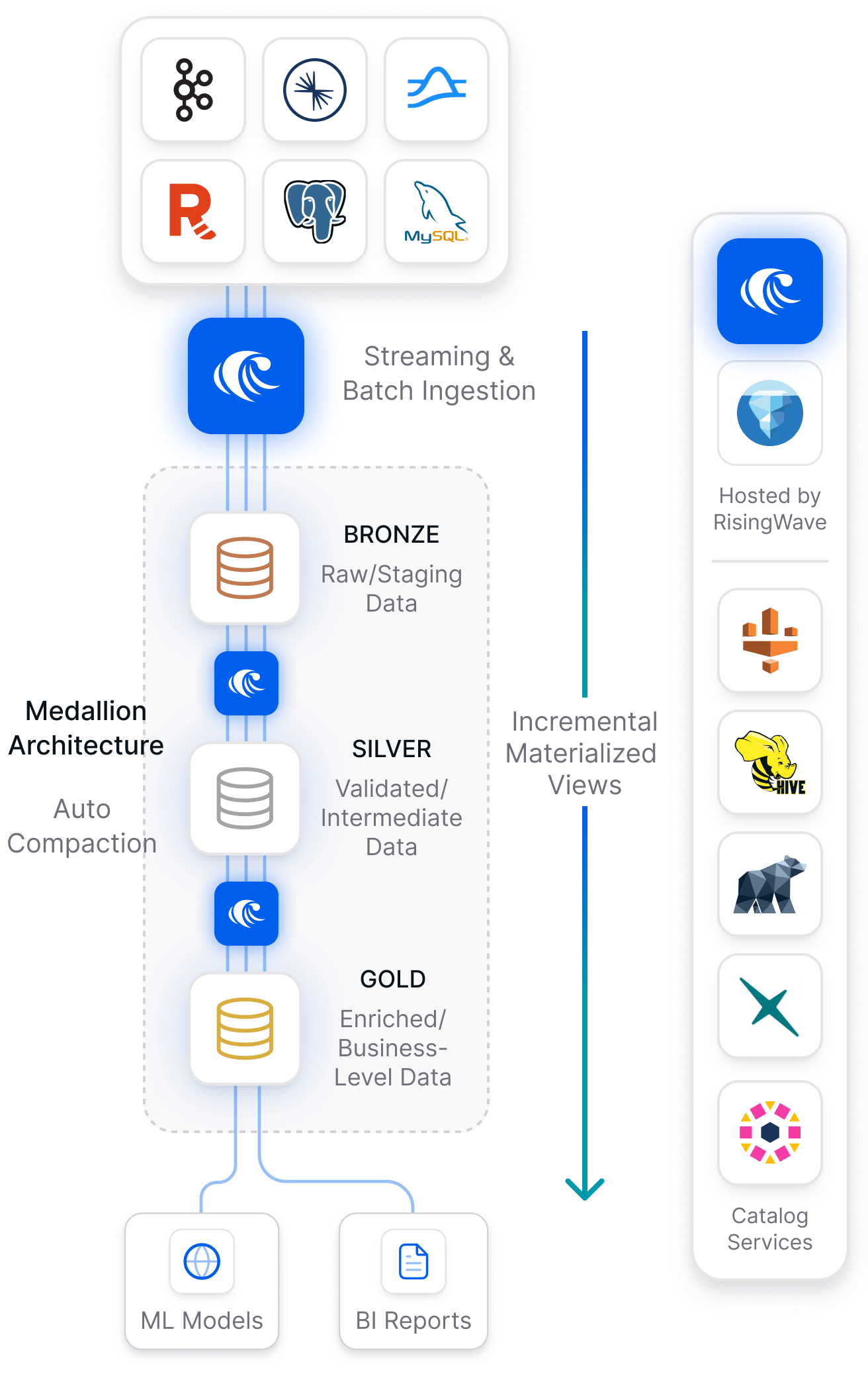
Ingest data from Kafka, CDC streams, or batch sources using Postgres-style SQL, and let us handle auto-compaction, schema evolution, and other challenges.
-- 1. Connect to your object store
CREATE CONNECTION my_iceberg_connection WITH (
type = 'iceberg',
warehouse.path = 's3://your-bucket/iceberg-stocks',
hosted_catalog = true -- No external catalog needed!
);
-- 2. Create your Iceberg table
CREATE TABLE stock_trades (
trade_id INT PRIMARY KEY,
symbol STRING,
trade_price DOUBLE,
trade_volume INT,
trade_time TIMESTAMP,
trade_value DOUBLE
) ENGINE = iceberg;
-- 3. Transform streaming data and stream results into your table
CREATE MATERIALIZED VIEW stock_trades_mv AS
SELECT
CAST(trade_id AS INT) AS trade_id,
TRIM(symbol) AS symbol,
CAST(price AS DOUBLE) AS trade_price,
CAST(volume AS INT) AS trade_volume,
CAST(trade_time AS TIMESTAMP) AS trade_time,
price * volume AS trade_value
FROM stock_trades_src
WHERE price > 0 AND volume > 0;
INSERT INTO stock_trades
SELECT * FROM stock_trades_mv;

RisingWave is built on open standards, so you’re free to ingest with us, query with others, or mix and match engines like Trino, Spark, and DuckDB. Your Iceberg tables stay fully portable and queryable—always.
read the documentation
Data Streaming Workloads? We’ve Heavily Optimized for Them!
Apache Iceberg wasn’t originally designed for streaming data, but we’ve fixed that once and for all! RisingWave Open Lake works beautifully for streaming. Whether your data comes from Kafka or Postgres/MySQL CDC, we take care of the hard parts: small files, equality deletes, exactly-once guarantees, backfilling, schema evolution, and more — so you don’t have to.

Rich Set of Connectors
RisingWave offers purpose-built streaming connectors equipped with built-in intelligence to detect back pressure, enabling efficient data ingestion from numerous sources in a decentralized manner.
Composable Data Pipelines
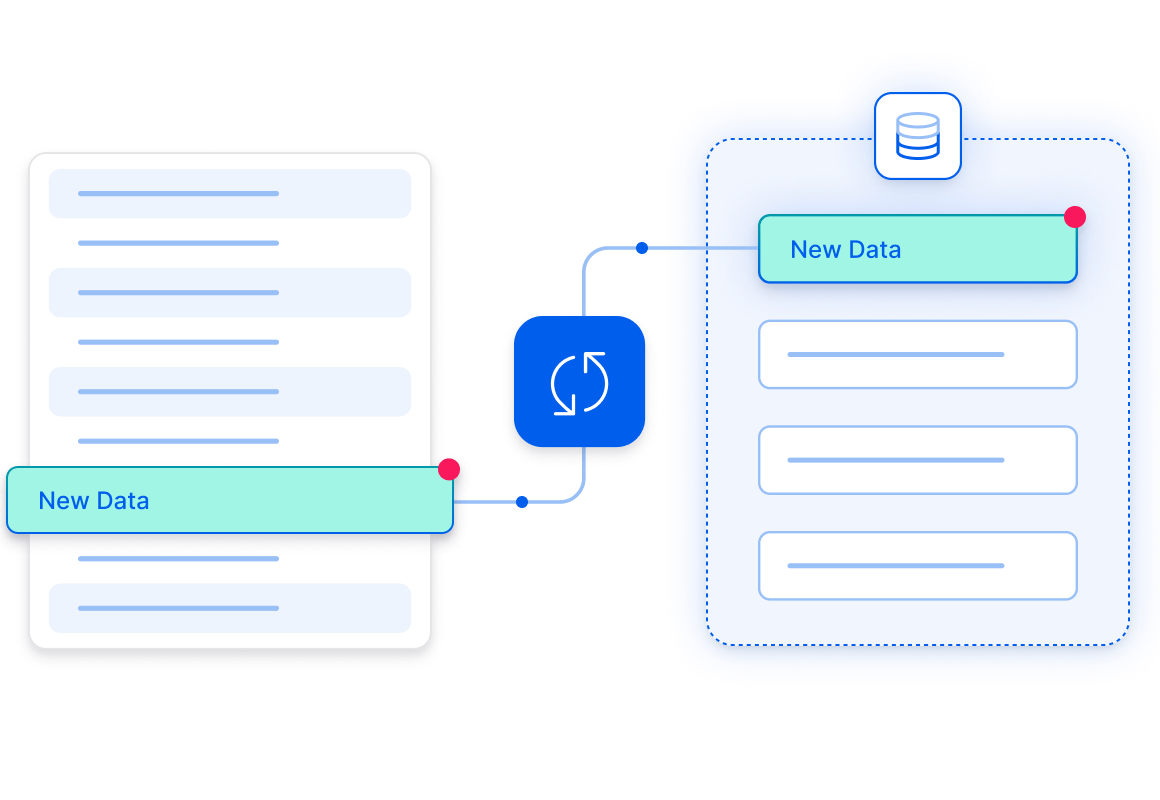
Live data has short shelf life. Incremental updates are triggered automatically in RisingWave to guarantee always fresh insights letting users get the most value of their data sets.
Incremental Processing for Ultra Low Latency
RisingWave makes data pipelines composable, allowing tables and views generated by one query to be seamlessly used as inputs for downstream queries.
Native Data Lake Formats Support
Interoperability is a core design principle of RisingWave. As Iceberg and Delta increasingly become the de facto standards for data lakehouse table formats, RisingWave provides robust read and write support for both.

We’ve Got Lots of Helpful Tips
and Resources for You


